
Every Sunday, the NPR host gets Will Shortz, which is Guru Crossword Guzzle New York Times, to test thousands of listeners in a long -term segment called Sunday puzzle. While it is written to be a solution without also Many prior knowledge, gunmen usually represent a challenge even for skilled contestants.
For this reason, some experts believe that they are a promising way to test the limits of problem -solving capabilities in artificial intelligence.
in A recent studyA team of researchers descending from Wilsley College, Opelin College, Texas University in Austin, North Eston University, Charles University and startups index created Amnesty International’s standard using puzzles from Sunday puzzles. The team says that their test revealed sudden visions, such as these thinking models – Openai’s O1, among other things – sometimes “surrender” and provide the answers they know are not correct.
“We wanted to develop a standard with the problems that human beings can understand with general knowledge only,” said Arjun Ghha, a faculty member of computer science at North Eston and one of the authors participating in the study, for Techcrunch.
The artificial intelligence industry is in the current dilemma. Most of the tests are commonly used to evaluate the artificial intelligence models of skills, such as efficiency in mathematics and doctoral science questions, which are not related to the ordinary user. At the same time, many criteria – even The criteria were released relatively recently They quickly approach the saturation point.
The advantages of the public radio competition game, such as Sunday’s puzzle, is that they do not test internal knowledge, and challenges are formulated so that the models cannot be derived from the “strong memory” to solve it, as explained.
Joe said: “I think what makes these problems difficult is that it is really difficult to make a meaningful progress in a problem until you solve them – when everything clicks together once,” said. “This requires a mixture of insight and the judiciary.”
There is no perfect standard, of course. Sunday’s puzzle is the United States and English only. Because the tests are available to the public, it is possible that the models trained on them can “cheat”, although its atmosphere says he has not seen evidence of this.
He added: “New questions are issued every week, and we can expect that the latest questions will be really invisible.” “We intend to maintain the new standard and follow how the performance of the model changes over time.”
On the standard of researchers, which consists of about 600 of Sunday shoes puzzles, thinking models such as O1 and Deepseek’s R1 excel over the rest. Thinking models completely verify the facts before giving the results, helping them avoid some of the pitfalls that usually increase the models of Amnesty International. The comparison is that thinking models take a little longer to reach solutions-secondly to longer minutes.
At least one model, Deepseek’s R1, gives solutions known to be wrong to some Sunday puzzle questions. R1 will literally mention “surrender”, followed by an incorrect answer that was randomly chosen – the behavior that this person can definitely associate.
Models make other strange choices, such as giving only a wrong answer to decline immediately, trying to disturb them better, and failing again. They also stumble “thinking” forever and providing meaningless explanations to obtain answers, or reaching a correct answer immediately, but then continued to think about alternative answers without a clear reason.
Joe said: “Regarding difficult problems, R1 literally says that he feels” frustrated. “It was funny to see how the model mimics what a person might say. It remains to see how” frustration “could affect the quality of the model’s results.

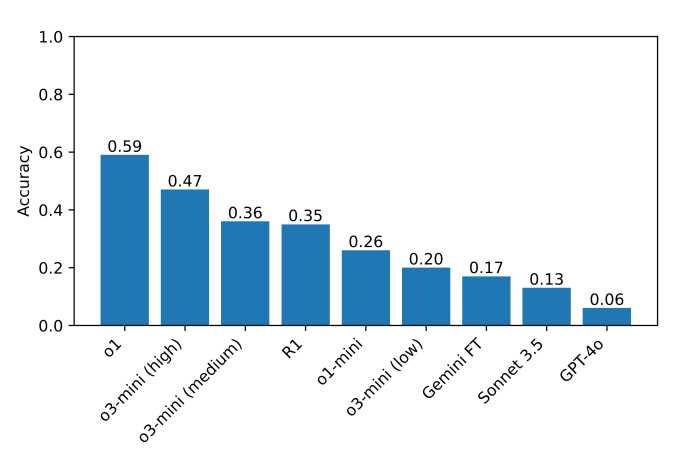
The currently best performance model in the standard is O1 with 59 %, followed by the recently released to the high “thinking voltage” (47 %). (R1 35 %.) As a next step, researchers plan to expand their tests to additional thinking models, which they hope to help identify areas where these models can be strengthened.
Joe said: “You do not need a doctorate to be good in thinking, so it should be possible to design thinking criteria that do not require knowledge at the doctorate level,” said. “The standard provides with a broader arrival to a broader group of researchers to understand and analyze the results, which in turn may lead to better solutions in the future. Moreover, since modern models are increasingly spread in the settings that affect everyone, we believe that everyone should be We are able to benefit from these models-and are not able to do so.